
最近有朋友问我这么一个面试题目:现在有一个非常庞大的数据,假设全是 int 类型。现在我给你一个数,你需要告诉我它是否存在其中(尽量高效)。
需求其实很清晰,只是要判断一个数据是否存在即可。但这里有一个比较重要的前提:非常庞大的数据。
常规实现
先不考虑这个条件,我们脑海中出现的***种方案是什么?我想大多数想到的都是用 HashMap 来存放数据,因为它的写入查询的效率都比较高。
写入和判断元素是否存在都有对应的 API,所以实现起来也比较简单。为此我写了一个单测,利用 HashSet 来存数据(底层也是 HashMap );同时为了后面的对比将堆内存写死:
-Xms64m-Xmx64m-XX:+PrintHeapAtGC-XX:+HeapDumpOnOutOfMemoryError
为了方便调试加入了 GC 日志的打印,以及内存溢出后 Dump 内存:
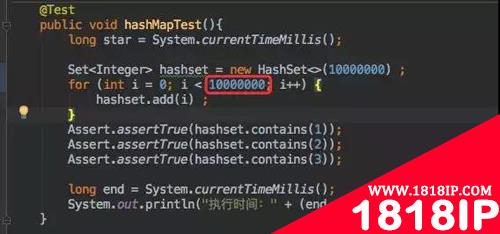
@Test
publicvoidhashMapTest(){
longstar=System.currentTimeMillis();
Set<Integer>hashset=newHashSet<>(100);
for(inti=0;i<100;i++){
hashset.add(i);
}
Assert.assertTrue(hashset.contains(1));
Assert.assertTrue(hashset.contains(2));
Assert.assertTrue(hashset.contains(3));
longend=System.currentTimeMillis();
System.out.println("执行时间:"+(end-star));
}
当我只写入 100 条数据时自然是没有问题的。还是在这个基础上,写入 1000W 数据试试:
执行后马上就内存溢出:
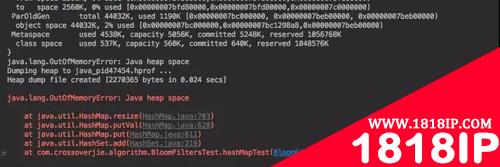
可见在内存有限的情况下我们不能使用这种方式。实际情况也是如此;既然要判断一个数据是否存在于集合中,考虑的算法的效率以及准确性肯定是要把数据全部 load 到内存中的。
Bloom Filter
基于上面分析的条件,要实现这个需求最需要解决的是如何将庞大的数据 load 到内存中。
而我们是否可以换种思路,因为只是需要判断数据是否存在,也不是需要把数据查询出来,所以完全没有必要将真正的数据存放进去。
伟大的科学家们已经帮我们想到了这样的需求。Burton Howard Bloom 在 1970 年提出了一个叫做 Bloom Filter(中文翻译:布隆过滤)的算法。
它主要用于解决判断一个元素是否在一个集合中,但它的优势是只需要占用很小的内存空间以及有着高效的查询效率。所以在这个场景下再合适不过了。
Bloom Filter 原理
下面来分析下它的实现原理。官方的说法是:它是一个保存了很长的二级制向量,同时结合 Hash 函数实现的。
听起来比较绕,但是通过一个图就比较容易理解了:
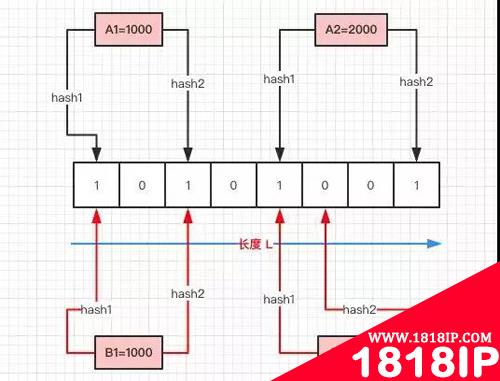
如上图所示:
- 首先需要初始化一个二进制的数组,长度设为 L(图中为 8),同时初始值全为 0 。
- 当写入一个 A1=1000 的数据时,需要进行 H 次 Hash 函数的运算(这里为 2 次);与 HashMap 有点类似,通过算出的 HashCode 与 L 取模后定位到 0、2 处,将该处的值设为 1。
- A2=2000 也是同理计算后将 4、7 位置设为 1。
- 当有一个 B1=1000 需要判断是否存在时,也是做两次 Hash 运算,定位到 0、2 处,此时他们的值都为 1 ,所以认为 B1=1000 存在于集合中。
- 当有一个 B2=3000 时,也是同理。***次 Hash 定位到 index=4 时,数组中的值为 1,所以再进行第二次 Hash 运算,结果定位到 index=5 的值为 0,所以认为 B2=3000 不存在于集合中。
整个的写入、查询的流程就是这样,汇总起来就是:对写入的数据做 H 次 Hash 运算定位到数组中的位置,同时将数据改为 1 。
当有数据查询时也是同样的方式定位到数组中。一旦其中的有一位为 0 则认为数据肯定不存在于集合,否则数据可能存在于集合中。
所以布隆过滤有以下几个特点:
- 只要返回数据不存在,则肯定不存在。
- 返回数据存在,但只能是大概率存在。
- 同时不能清除其中的数据。
***点应该都能理解,重点解释下 2、3 点。为什么返回存在的数据却是可能存在呢,这其实也和 HashMap 类似。
在有限的数组长度中存放大量的数据,即便是再***的 Hash 算法也会有冲突,所以有可能两个完全不同的 A、B 两个数据***定位到的位置是一模一样的。
这时拿 B 进行查询时那自然就是误报了。删除数据也是同理,当我把 B 的数据删除时,其实也相当于是把 A 的数据删掉了,这样也会造成后续的误报。
基于以上的 Hash 冲突的前提,所以 Bloom Filter 有一定的误报率,这个误报率和 Hash 算法的次数 H,以及数组长度 L 都是有关的。
自己实现一个布隆过滤
算法其实很简单不难理解,于是利用 Java 实现了一个简单的雏形:
- 首先初始化了一个 int 数组。
- 写入数据的时候进行三次 Hash 运算,同时把对应的位置置为 1。
- 查询时同样的三次 Hash 运算,取到对应的值,一旦值为 0 ,则认为数据不存在。
代码如下:
publicclassBloomFilters{
/**
*数组长度
*/
privateintarraySize;
/**
*数组
*/
privateint[]array;
publicBloomFilters(intarraySize){
this.arraySize=arraySize;
array=newint[arraySize];
}
/**
*写入数据
*@paramkey
*/
publicvoidadd(Stringkey){
intfirst=hashcode_1(key);
intsecond=hashcode_2(key);
intthird=hashcode_3(key);
array[first%arraySize]=1;
array[second%arraySize]=1;
array[third%arraySize]=1;
}
/**
*判断数据是否存在
*@paramkey
*@return
*/
publicbooleancheck(Stringkey){
intfirst=hashcode_1(key);
intsecond=hashcode_2(key);
intthird=hashcode_3(key);
intfirstIndex=array[first%arraySize];
if(firstIndex==0){
returnfalse;
}
intsecondIndex=array[second%arraySize];
if(secondIndex==0){
returnfalse;
}
intthirdIndex=array[third%arraySize];
if(thirdIndex==0){
returnfalse;
}
returntrue;
}
/**
*hash算法1
*@paramkey
*@return
*/
privateinthashcode_1(Stringkey){
inthash=0;
inti;
for(i=0;i<key.length();++i){
hash=33*hash+key.charAt(i);
}
returnMath.abs(hash);
}
/**
*hash算法2
*@paramdata
*@return
*/
privateinthashcode_2(Stringdata){
finalintp=16777619;
inthash=(int)2166136261L;
for(inti=0;i<data.length();i++){
hash=(hash^data.charAt(i))*p;
}
hash+=hash<<13;
hash^=hash>>7;
hash+=hash<<3;
hash^=hash>>17;
hash+=hash<<5;
returnMath.abs(hash);
}
/**
*hash算法3
*@paramkey
*@return
*/
privateinthashcode_3(Stringkey){
inthash,i;
for(hash=0,i=0;i<key.length();++i){
hash+=key.charAt(i);
hash+=(hash<<10);
hash^=(hash>>6);
}
hash+=(hash<<3);
hash^=(hash>>11);
hash+=(hash<<15);
returnMath.abs(hash);
}
}
实现逻辑其实就和上文描述的一样。下面来测试一下,同样的参数:
-Xms64m-Xmx64m-XX:+PrintHeapAtGC
@Test
publicvoidbloomFilterTest(){
longstar=System.currentTimeMillis();
BloomFiltersbloomFilters=newBloomFilters(10000000);
for(inti=0;i<10000000;i++){
bloomFilters.add(i+"");
}
Assert.assertTrue(bloomFilters.check(1+""));
Assert.assertTrue(bloomFilters.check(2+""));
Assert.assertTrue(bloomFilters.check(3+""));
Assert.assertTrue(bloomFilters.check(999999+""));
Assert.assertFalse(bloomFilters.check(400230340+""));
longend=System.currentTimeMillis();
System.out.println("执行时间:"+(end-star));
}
执行结果如下:

只花了 3 秒钟就写入了 1000W 的数据同时做出来准确的判断。
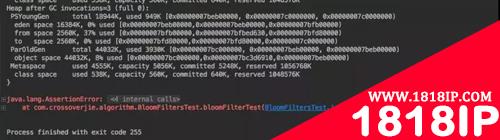
当让我把数组长度缩小到了 100W 时就出现了一个误报,400230340 这个数明明没在集合里,却返回了存在。
这也体现了 Bloom Filter 的误报率。我们提高数组长度以及 Hash 计算次数可以降低误报率,但相应的 CPU、内存的消耗就会提高;这就需要根据业务需要自行权衡。
Guava 实现
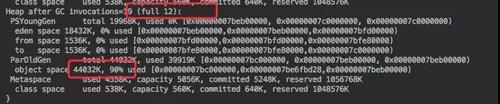
刚才的方式虽然实现了功能,也满足了大量数据。但观察 GC 日志非常频繁,同时老年代也使用了 90%,接近崩溃的边缘。
总的来说就是内存利用率做的不好。其实 Google Guava 库中也实现了该算法,下面来看看业界权威的实现:
-Xms64m-Xmx64m-XX:+PrintHeapAtGC
@Test
publicvoidguavaTest(){
longstar=System.currentTimeMillis();
BloomFilter<Integer>filter=BloomFilter.create(
Funnels.integerFunnel(),
10000000,
0.01);
for(inti=0;i<10000000;i++){
filter.put(i);
}
Assert.assertTrue(filter.mightContain(1));
Assert.assertTrue(filter.mightContain(2));
Assert.assertTrue(filter.mightContain(3));
Assert.assertFalse(filter.mightContain(10000000));
longend=System.currentTimeMillis();
System.out.println("执行时间:"+(end-star));
}
也是同样写入了 1000W 的数据,执行没有问题。
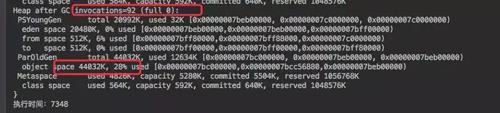
观察 GC 日志会发现没有一次 fullGC,同时老年代的使用率很低。和刚才的一对比这里明显的要好上很多,也可以写入更多的数据。
那就来看看 Guava 它是如何实现的?构造方法中有两个比较重要的参数,一个是预计存放多少数据,一个是可以接受的误报率。 我这里的测试 demo 分别是 1000W 以及 0.01。
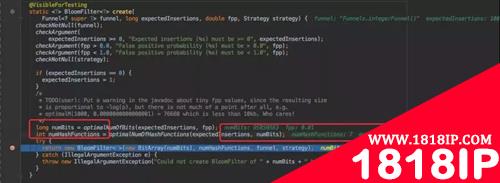
Guava 会通过你预计的数量以及误报率帮你计算出你应当会使用的数组大小 numBits 以及需要计算几次 Hash 函数 numHashFunctions 。这个算法计算规则可以参考维基百科。
put 写入函数
真正存放数据的 put 函数如下:
- 根据 murmur3_128 方法的到一个 128 位长度的 byte[]。
- 分别取高低 8 位的到两个 Hash 值。
- 再根据初始化时的到的执行 Hash 的次数进行 Hash 运算。
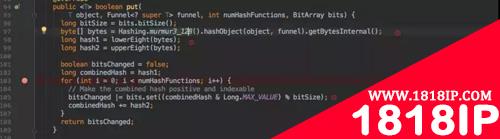
bitsChanged|=bits.set((combinedHash&Long.MAX_VALUE)%bitSize);
其实也是 Hash 取模拿到 index 后去赋值 1,重点是 bits.set() 方法。
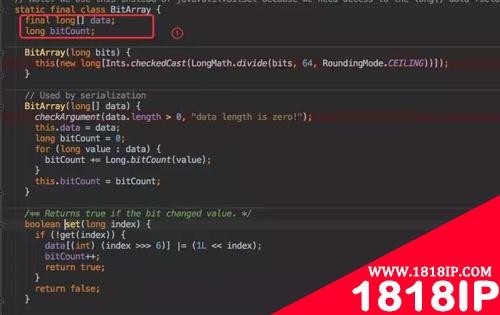
set 方法是 BitArray 中的一个函数,BitArray 就是真正存放数据的底层数据结构,利用了一个 long[]data 来存放数据。
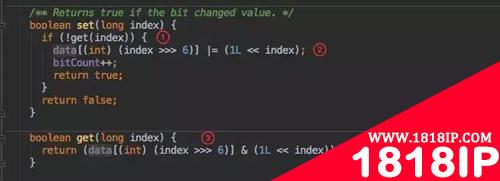
所以 set() 时候也是对这个 data 做处理:
- 在 set 之前先通过 get() 判断这个数据是否存在于集合中,如果已经存在则直接返回告知客户端写入失败。
- 接下来就是通过位运算进行位或赋值。
- get() 方法的计算逻辑和 set 类似,只要判断为 0 就直接返回存在该值。
mightContain 是否存在函数
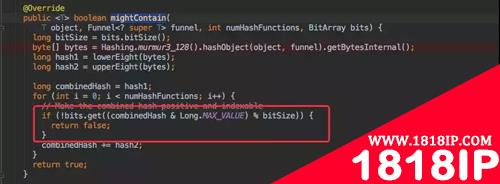
前面几步的逻辑都是类似的,只是调用了刚才的 get() 方法判断元素是否存在而已。
总结
布隆过滤的应用还是蛮多的,比如数据库、爬虫、防缓存击穿等。特别是需要精确知道某个数据不存在时做点什么事情就非常适合布隆过滤。
本示例代码参考这里:https://github.com/crossoverJie/JCSprout

