
最近一直在思考一个问题:如何为一个数据库建立性能模型?作为一名DBA来说,我们面临的一个巨大挑战是:如何保证数据库的性能可以满足快速变化的应用的需求,如何在数据量和访问量持续增长的情况下,保证应用的响应时间和数据库的负载处在合理的水平下。我们可能会经常面对以下的问题:某个SQL每秒要执行100次,响应时间是多少?某个应用发布后,对数据库的影响如何?所以,评估应用对数据库所产生的影响,优化应用并预测风险,保证数据库的可用性和稳定性,这是应用DBA真正有价值的地方。
响应时间为中心:
如果要选择一个评价系统优劣的性能指标,毫无疑问应该是响应时间。响应时间是客户体验的***要素,所有的优化都应该为降低响应时间而努力。对于数据库系统也是如此,我们优化系统,优化SQL,最终目标都是为了降低响应时间,单位时间内可以处理更多的请求。
数据库时间模型:
响应时间一般分为服务时间(Service time)和等待时间(Wait time),服务时间指进程占用CPU的时间,包括前台进程(Server process)和后台进程(Backgroud process),我们一般只关注前台进程占用的CPU time。等待时间包括很多类型,一般最常见的是IO等待和并发等待,IO等待包括sequential read,scattered read和log file sync等等,而并发等待主要是latch和enqueue。SQL execute elapsed time指用户进程执行SQL的响应时间,包含CPU time和wait time。
以下是Oracle数据库的时间模型:

在Oracle系统中,我们可以利用AWR或Statspack报告,看到数据库的时间信息:
| Statistic Name | Time (s) | % of DB Time |
|---|---|---|
| sql execute elapsed time | 3,062.17 | 91.52 |
| DB CPU | 2,842.08 | 84.95 |
| parse time elapsed | 25.87 | 0.77 |
| PL/SQL execution elapsed time | 11.75 | 0.35 |
| sequence load elapsed time | 7.55 | 0.23 |
| hard parse elapsed time | 5.06 | 0.15 |
| connection management call elapsed time | 3.13 | 0.09 |
| hard parse (sharing criteria) elapsed time | 0.04 | 0.00 |
| repeated bind elapsed time | 0.01 | 0.00 |
| PL/SQL compilation elapsed time | 0.00 | 0.00 |
| DB time | 3,345.74 | |
| background elapsed time | 204.91 | |
| background cpu time | 72.30 |
DB time是整个数据库用户进程消耗的总时间,是从***项到第十项时间的总和(从sql execute elapsed time到PL/SQL compilation elapsed time),但是我们会发现这十项时间的总和比DB Time要大一些,这是因为部分时间信息有重叠的部分,比如SQL execute elapsed time就包括了很大一部分DB cpu的时间。而background elapsed time和background cpu time则是Oracle后台进程消耗的时间和cpu time。
数据库响应时间分析:
数据库系统的响应时间由四个要素决定:CPU,IO,内存和网络,其中CPU和IO是最重要的因素。与之相比,内存与网络则简单很多,因为通常情况下,对于一个调优的系统来说,内存访问的延迟时间非常小(100 ns以下,1 ms=1000000 ns)相比较CPU和IO几乎可以忽略。而网络延迟则通常是一个常数,比如在一个数据中心的情况下,网络的延迟一般在3ms以下,如果存在多数据中心的情况,网络延迟可能会超过20ms,所以对于一个分布式系统来说,网络延迟是必须要考虑的问题。
在这里,我们不考虑分布式系统,并且忽略内存的访问延迟,重点分析CPU和IO,我们看以下数据库的AWR片段:
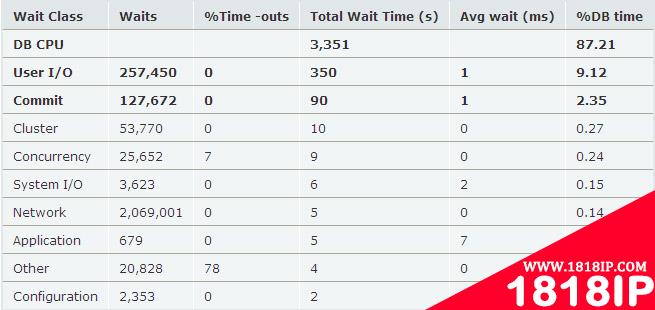
我们看到这个系统中DB CPU占整个DB time的87.21%,User I/O占整个DB time的9.12%,commit相关的IO等待占2.35%(主要是log file sync),CPU和IO占用了整个DB time的96.68%。由于DB CPU所占的比例很高,所以这个数据库系统是CPU intensive类型,这里的DB CPU主要是执行SQL的服务时间。
我们再看另外的一个数据库的AWR片段:
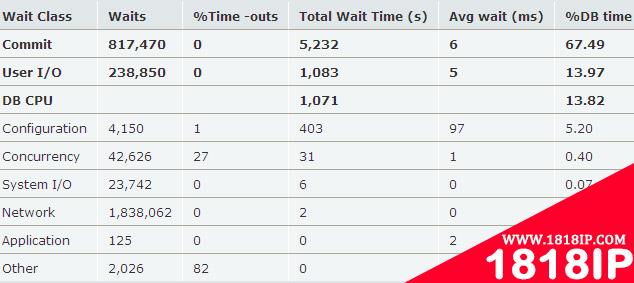
我们看到,Commit和User I/O占DB time的81.46%,而DB CPU只占13.82%,所以这个数据库系统是IO instensive类型的。
Physical read
Physical read是指Oracle在buffer cache中没有找到相应的block,需要从IO子系统读取相应的block的过程,对应的IO称为物理IO,物理读数量代表物理IO读取的block数量。因为一般IO子系统都是慢速的磁盘,所以物理IO对整体响应时间的影响非常大,如果发生大量的物理IO,整个系统的响应时间会变得很差。系统的IO子系统可能是文件系统,裸设备或者ASM,底层硬件可能是SAN存储,NAS存储或者普通SAS磁盘等等。为了提高响应时间,通常在物理磁盘与Oracle之间增加cache层,对于Oracle来说,物理IO并不一定是真正访问磁盘,很可能是访问文件系统cache,存储的cache等等。
不管IO subsystem是什么,Oracle只关心物理IO的响应时间。通过AWR报告,我们可以看到物理IO的响应时间:
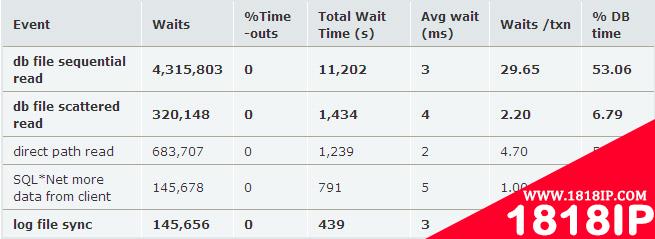
db file sequential read(单块读,随机IO)的平均响应时间为3ms,db file scattered read(多块读,连续IO)的平均响应时间是4ms,logfile file sync的平均响应时间是3ms,前两者的Wait class是User I/O,代表用户进程读操作的响应时间,logfile sync的wait class是Commit,代表lgwr进程写redo的响应时间,因为用户commit必须完成log file sync的操作,所以它也会直接影响用户进程写操作的响应时间。
关于物理IO的响应时间,我们有一个经验值。对于Sequential read和Scattered read,我们认为小于10ms属于正常状态,而大于10ms则认为IO subsystem的响应延迟过大。所以我们在衡量存储系统的性能时,只有响应时间在10ms以下的IO我们认为是有效的。这里有一个有趣的现象,就是sequential read和scattered read的响应时间几乎相差无几,也就是说随机IO读取8K数据和连续IO读取128K数据,响应时间差别很小,这是由磁盘的机械特性造成的,延迟时间=寻道时间+
对于log file sync的响应时间,因为用户commit必须完成log file sync,所以整个系统的写操作的响应时间都取决于它的响应时间,而且从整个数据库系统的角度去看,log file sync几乎是串行的,所以这个响应时间对写操作影响非常大,我们的经验值是必须保证在5ms以下,如果超过5ms整个系统的写操作都会受到严重的影响。
Logical read
Logical read是Oracle从buffer cache中读取block的过程,对应的IO称为逻辑IO,逻辑读数量代表逻辑IO读取的block数量。因为Oracle必须首先将block读入buffer cache中(direct path read除外),所以逻辑读数量包含了物理读数量。对于一个SQL来说,逻辑读数量是衡量其性能的标准,而不是物理读。虽然物理IO的响应延迟比逻辑IO大很多,但是物理读数量会随着执行次数而变化(频繁读取导致block被缓存在buffer cache中)。对于一个系统也是如此,逻辑读应该是数据库性能评估模型的核心,我们需要建立逻辑读与响应时间的对应关系。
每个逻辑读的响应时间是多少,这是一个巨大的挑战。因为每个逻辑读背后隐藏了很多动作,可能包括物理读,等待事件,CPU time等等。我对很多数据库的AWR报告做了分析,期望根据经验值建立一个简化的模型。我们假设一个数据库如果是充分调优的,除CPU time和IO以外的等待时间应该尽可能少(应小于DB time 10%)。在这个前提下,我们只关心CPU time和IO的影响,并将系统分为三类:CPU密集型,IO密集型和混合型:
1.IO密集型
User IO 85% DB CPU 5% 每逻辑读响应时间0.1-0.5ms
2.CPU密集型
DB CPU 85% User IO 10% 每逻辑读响应时间小于0.01ms
3.混合型
User I/O 60% DB CPU 20% 每逻辑读响应时间0.05-0.1ms
以上数据是根据很多个典型数据库的AWR报告计算出来的经验值,计算公式很简单:DB time/逻辑读=每逻辑读响应时间。因为并没有考虑硬件和OS上的差异,所以这个数值并不是特别准确,但我们还是可以发现一些规律:随着IO所占比例从10%增加到85%,响应时间也从小于0.01ms到0.5ms。
预测系统瓶颈
对于数据库来说,IO子系统对性能影响非常大,必须保证在一定的IO的压力下,响应延迟控制在合理的范围内(前面说的10ms和5ms)。因为每块磁盘可以承受的IOPS是基本确定的,比如15K的SAS磁盘,在响应延迟不超过10ms的前提下,可以提供150个IOPS,如果不考虑cache的影响,整个存储子系统的IOPS是比较容易计算的。我们可以在系统上线前,进行大量充分的测试,建立存储IOPS与响应延迟的模型,这样我们就可以预测出性能出现拐点的风险,提前做出扩容的判断。在AWR报告中,我们可以得到每秒的物理IO的数量和响应时间,可以方便的实现性能监控和趋势预警。
评估CPU的容量瓶颈相对简单,Oracle中CPU time的计算是每个CPU耗费时间的总和,如果有16颗(核)CPU,1个小时理论上可以提供3600×16=57600s CPU time,不超过57600s CPU time我们可以认为不会在CPU上排队,系统不会出现CPU瓶颈。但是需要注意的是,除了用户进程使用CPU以外,操作系统也需要占用CPU资源,用来管理内存和进程调度等。我们在OS上看到的CPU使用率中的sys部分就是系统占用的CPU资源,所以应该考虑至少保留10-20%的CPU资源给OS使用。
并发访问对数据库的影响
Oracle是一个Disk-based database,设计的出发点就是大部分数据在外部存储中,而只有小部分数据被cache在buffer中,它既不同于Memcache这类KV cache,也不同于timesten这类In-memory database。所以,就算是所有的数据都可以被cache在buffer中,在高并发访问的情况下,也可能会出现大量的latch等待,最常见的情况就是cache buffer chain。当大量并发访问同一块数据时,就很可能会出现cache buffer chain的latch争用,也就是我们常说的“热点”。
需要注意的是:Oracle中的latch等待分为spin和sleep两个部分,spin消耗cpu time,而sleep则是等待时间。所以大量的latch等待不仅仅会产生大量的等待时间,而且会消耗大量的CPU time。
Oracle是一个为并发操作而设计的数据库,大量的并发读写请求,可能会带来额外的性能消耗。比如读取一部分频繁修改的数据,Oracle为了保证一致性读的需要,会利用undo信息构造产生大量CR block,同时会产生大量的逻辑读,这样会消耗额外的CPU和响应时间。
存储也可能存在热点的问题,需要前期对存储系统充分的优化,常见的手段是利用RAID技术,将数据分散在不同的磁盘上,防止出现“热点”盘。Oracle ASM提供了Rebalance的功能,允许DBA将存储中的的数据重新分布,达到消除热点的目的。
总之,Oracle是一个可以提供大量并发读写访问的数据库系统,但是在很多地方,Oracle又不得采用一些串行的控制手段,比如latch,enqueue和mutex,我们要做的就是尽量降低这些串行控制对数据库整体性能的影响。
数据库优化原则
基于响应时间的Oracle优化原则:尽量减少等待时间(Wait time),提高服务时间(Service time)。这也是基于Oracle等待事件的分析方法的基本原则:尽量消除各种等待事件对系统的影响,从而提高系统性能和响应时间。
如果数据库系统除了CPU和IO以外的等待时间超过DB time的5%以上的话,可能存在某些性能问题,需要DBA采用等待事件的分析方法,对系统或应用进行优化。
–EOF–
后记:为什么要写这么一个主题,因为最近和一位同事探讨机器自动审核SQL的问题,就想建立一个简单的模型,用来开发一个SQL审核工具,开发人员通过工具和预先建立好的模型,就可以确定这个SQL是否存在性能风险。之前我们在做SQL优化的时候,只是关注这个SQL本身是否优化,逻辑读是多少。但是,很少有人把逻辑读和响应时间之间的关系建立起来,我试图想回答这个问题。
关于容量规划和风险预测其实是一个很有意义的命题,但是我们很多时候都局限在一些具体的技术细节中,而忽略了对整个系统容量的把握,事实上,这也是非常难的一件事。也许到目前为止,我根本没有达到建立“模型”的程度,但是我试图将这些方方面面的因素联系起来,提供一些有用的经验值给大家,我觉得这个挺有意义。
在这篇文章中,我提到了几个有意义的经验值,这是我根据很多数据库AWR中的信息计算出来的,虽然不保证完全准确,但是我觉得基本是靠谱的。建议每个DBA都应该从AWR中找到这些信息,并判断自己的数据库属于哪种类型,瓶颈在哪里,是否存在性能风险。当面对诸如“硬件是否能够满足性能需求”,“系统明年是否需要扩容”,“应用是否会对系统产生影响”此类问题时,我们可以用这些经验值给出一个判断。
关于这个命题,目前只是一个阶段性的结果,我还会继续思考。如果大家有兴趣,欢迎和我一起探讨这个话题。
